Når man vil prøve at forbedre performance i et softwaresystem, skal man først og fremmest vide hvad det er man vil forbedre. Hvordan ser en kørsel af systemet ud mht. latency hen over længere tid? Det er sjældent at man sætter performance testkørsler i gang, måler og samler data så det kan visualiseres. Det vil dog bringe større forståelse af systemets latency og throughput, hvis man kan se et overordnet billede af svartiderne for ens system.
Latency histogrammer
Svartider – dvs. systemets latency – er vigtig at forstå, og for at kunne forstå det i detaljer kan man indsamle data til et histogram.
Det er her Latency Histogrammer kommer ind i billedet. Man kører en masse forskellige performance tests hen over flere dage elle ruger (på den samme software version), og derefter plotter man al data ind i ét histogram, med latency i millisekunder ud af x-aksen, og antal forekomster af hver svartid op ad y-aksen.
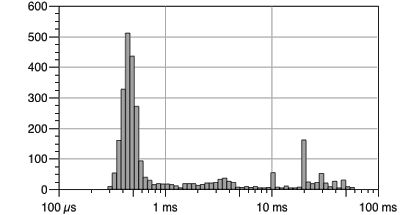
På billedet ses at de fleste svartider er under 1 ms, mens der er en del spikes som ligger mellem 10 ms og 100 ms. Det er disse spikes, der i det efterfølgende arbejde skal kigges nærmere på ved analysere systemet/netværket/3. parts komponenter osv. – således at disse spikes enten bliver fjernet eller gjort mindre.
Man kan også gøre som jeg beskrev i forrige indlæg om performance testing, og sætte et continuous performance testing system op, som eksempelvis kører hver nat og til sidst opsamler data fra testene og tegner et latency histogram. På den måde kan man hurtigere opdage om der er blevet introduceret fejl i koden, der har afgørende indvirkning på latency – både godt og skidt.
Hvis man først performance tester og tegner latency histogrammer i slutningen af en release, så kan det være ret besværligt og tidskrævende at rulle koden tilbage til tidligere versioner for at finde ud af hvilket commits, der medførte en forringelse af performance. Hvis et continuous performance test system var blevet sat op fra starten af projektet, så kunne udviklerne allerede dagen efter se, hvis en fejl var blevet introduceret der havde en indvirkning på performance. Og det er forholdsvis billigt at få sat op, i forhold til den tid det tager at debugge og analysere performance problemer sent i forløbet.
Stress Test
Der findes mange forskellige typer performance tests. Formålet med specielt stress tests er at finde ud af hvor meget der skal til for at belaste et system mest muligt, dvs. finde ud af hvad den størst mulige workload er. Udfør testen ved at stresse systemet mere og mere, dvs. fodre systemet hele tiden med en øget mængde data, hvorefter man på et tidspunkt vil nå et maksimum – som giver sig til udtryk ved at svartiderne bliver meget langsomme, eller at throughput går mod nul, eller at køerne i systemet bliver fyldt op og der er ikke nok ressourcer til at tage fra køerne hurtigt nok. Dette kan så igen medføre en dominoeffekt, hvor der opstår fejl andre steder i systemet. Stress tests kan hjælpe med at finde de svageste led i systemet, hvorefter man kan reparere disse og få et mere fejltolerant system.
Når man har brug for at finde flaskehalse eller lignende i ens applikation (og dermed løse problemer relateret hertil), så brug en profiler såsom JVisualVM.
Hvad har du af erfaringer når det gælder performance testing? Både gode og dårlige.
Gil Tene havde en temmeligt god talk om latency-testing på React 2014,
https://www.youtube.com/watch?v=9MKY4KypBzg
Hans HDRHistogram er virkeligt rart at have for at kunne teste latency og fordelen ved det er at du får funktionen for distributionen i stedet for et histogram, og det kan nogengange være lettere at læse. Specielt omkring 99.99 percentilen og lignende. Det er ofte par par voldsomme outliers der skaber alle problemerne.
Hans anden pointe, coordinated omission, er også værd at nævne. Grundliggende er problemet her at en langsom query (altså den med 100ms+) kan medføre at andre queries bliver sat i kø bag den, men måler du ikke queue-sojourn tiden med, så er billedet af din latency forkert. Den query du ser der tager 1ms? Well, den har siddet i kø bag 3 der tog over 10ms, og nu er dens lower bound 31ms i praksis.
I dag laver jeg stort set ikke professionelle systemer uden at instrumentere dem, så du har probes overalt i dem. Det gør det meget nemmere at se ting. f.eks. at Den ene databasecluster altid svarer 20ms langsommere end den anden 🙂
Åh, jeg har testet Performance, load og stress på store løsninger med dyre værktøjer ofte til ingen verdens forretningsværdi. Een gang var det rent poliltik, en anden gang standard systemets indbyggede locks der var humlen i det hele. SOA systemet havde nemlig probes i koden, så der var ikke meget at hente :).
Man kan efterhånden kaste loadbalancere, hardware og cloud løsninger på standby som mitigering af performance risks. Moderne løsninger bruger ofte SOASTA, SmartBear – hvis da ikke man går skridtet videre til at bruge produktionsmiljøet aktivt med ChaosMonkies, simean army mv.
For det er helheden i løsningen man er efter, og den kan sjældent simuleres eller estimeres. Hvor mange klikker på dit site efter din TV reklame? Hvilken latency har din app på et IC3 tog over Fyn? Hvilke (social media) tredie parts integrationer, kan du ikke simulere i dit CI performance miljø.
Brugen af NemID for at se skatteoplysninger sidste år blev frigivet samme dag, der var melodigrandprix (for de voksne) – og presset på systemer fulgte showets gang. OG så var der dengang Ellen fik twitter til at gå ned med et enkelt foto. http://blog.smartbear.com/performance/breaking-it-down-with-scott-barber-how-ellen-degeneres-broke-twitter/
Lav lige en GivenWhenThen på den på forhånd 🙂
Hvis jeg designede et stort system fra bunden nu, ville jeg helt sikkert også tænke instrumentering og performance-tests ind fra starten. Det kan godt være lidt svært og kunstigt at proppe ind i et for længst etableret system.
Det passer vel egentlig meget godt med test-driven development. Man kunne godt have performancetests klar fra starten eller i hvert fald meget tidligt i processen, i hvert fald hvis der er et væsentligt performancekrav til systemet.
Det mega svære ved performance tests (load og tress ditto) er at vi oftere og oftere skal have hele økosystemet med incl. bagrundsbelastninger og andet godt. Latency lokalt er godt, men det batter mere at den løsning performer når der kører kampagner, at den kører på en 3G tog forbindelse over Fyn. Sidste år ved denne tid blev årsopgørelsen frigivet samme dag som der var melodi grandprix (for de voksne) – loadet på skat fulgte programmets pauser. Interesant at monitorere men totalt umuligt at lave en GivenWhenThen på. Ligeledes fik et enkelt foto hele Twitter til at gå ned (og det var ikke det af Helle T): http://blog.smartbear.com/performance/breaking-it-down-with-scott-barber-how-ellen-degeneres-broke-twitter/
Det er derfor NetFlix bruger chaos monkies mv, og hvorfor flere og flere bruger SOASTA og SmartBear til det store overblik. Men latency lokalt er bestemt en start. Det er bare ikke sikkert at det gør en forskel hvis der er locks i under systemet – som i øvrigt er COTS #beenThere.