English version: http://www.tigerteam.dk/2014/soa-synchronous-communication-data-ownership-and-coupling/
Microservices: Micro services: Det er ikke (kun) størrelsen der er vigtigt, det er (også) hvordan du bruger dem – Del 1
Jeg læste den anden dag, at Arbejdsskadestyrelsens nye system Proask, var det første større projekt der skulle realisere Beskæftigelsesministeriets strategiske beslutning om Service Orienteret Arkitektur (SOA). For dem der ikke har hørt om Proask, så er det endnu et stærkt forsinket offentligt projekt der, lige som de fleste andre offentlige projekter, forsøger at løse et meget stort problem i en stor bid. Der kan skrives meget om den tilgang, men det jeg vil fokusere på her er deres indgangsvinkel til SOA. I en relateret artikel fortælles der om at det nye Proask system er 5 gange langsommere end deres gamle system fra 1991. Proask projektet blev initieret i 2008. Det fik mig til at tænke tilbage på at andet (privat) SOA prestige projekt fra samme periode, som jeg deltog i som arkitekt for en underleverandør. Hele projektet var bygget op omkring SOA med mange delsystemer der skulle levere services. Hele arkitekturen var bygget op omkring en ESB der skulle agere tovholder mht. mapping og koordinering. Al kommunikation skete som synkrone WebService kald over HTTP(S). Altså klassisk SOA anno 2003-201? (trist nok er synkrone kald stadig den fremherskende integrationsform). Denne SOA realisering var også præget af rigtig dårlig performance, høj latens tid og ringe stabilitet.
Men hvorfor? Grunden skal findes i den måde man havde valgt at dele servicene op og ikke mindst i at man havde valgt at kommunikere synkront mellem de forskellige services og at man benyttede lagdelt SOA.
Hvad er der så galt med synkron integration?
Som sådan ikke noget. Det kommer an på hvordan og hvornår det bliver brugt. Hvis vi integrerer med en ældre applikation er der tit andet at gøre end at benytte det synkrone API (hvis et offentligt API overhovedet findes) der bliver stillet rådighed. Den form for integration sker i forvejen på bagkanten og API, data ejerskab og funktionalitet som denne applikation besidder er så at sige hugget i sten og svært/umuligt at ændre. Det er også vigtigt at indse at en sådan integration falder ind under kategorien “Integration by a bunch of WebServices” eller i bedste fald “Enterprise Application Integration (EAI)” (over WebServices/REST/etc.). Synkron integration mellem Services har ikke noget med SOA at gøre, da det bryder flere af de grundlæggende SOA principper.
SOA Principper?
Don Box (manden bag SOAP) fremsatte de 4 Principper for Service Orientation (4 tenets of service orientation):
- Grænser er eksplicitte (Boundaries are explicit)
- Services er autonome (Services are autonomous)
- Services deler skema og kontrakt, ikke klasser (Services share schema and contract, not class)
- Service kompatibilitet bygger på politikker (Service compatibility is based on policy)
Princip 1 og 2 bliver let overset og fokus har oftest været på princip 3 og til dels 4.
For mig er Princip 1 og 2 meget vigtige, da det er dem der skal være med til at guide os når vi designer services og tildeler dem ansvar. De er samtidig med til at give os svaret på hvorfor synkrone kald mellem Services bør undgås.
Første SOA Princip: Grænser er eksplicitte
At en services grænse er eksplicitte kan betyde forskellige ting for mange mennesker.
Det jeg ligger vægt på er: En services ansvar både mht. data og funktionalitet er klart afgrænset og sammenhængende (cohesion).
Med sammenhængende tænker jeg både på at kommunikations mæssig samhørighed (logik og de data logikken arbejder på hører til samme service), lagdelt samhørighed (en service er ansvarlig for data persistens, håndtering af sikkerhed, brugergrænseflade, etc.) samt Temporal samhørighed (de dele/aspekter der er involveret i håndtering af en services funktion er grupperet sammen således at de kan udføres tæt på hinanden i tid). Uden kommunikations mæssig samhørighed og lagdelt samhørighed er det umuligt at opnå Temporal samhørighed hvilket er forudsætningen for Andet SOA Princip “Services er autonome”.
De fleste af os er opflaskede med monolitiske applikationer drevet af databaser. Det jeg har observeret er at denne type applikationer har en tends til at ende op med en stor/tyk data model hvor alt ender med at været koblet til hinanden (fordi det er nemt og bekvemt at lave en join tabel, en union i en query, etc.).
Det starter oftest simpelt men med tiden ender med nemt med en big bowl of mud:
Stille og roligt vokser vores data modeller i størrelse til de tilsidst bliver forvirrende og rodede
En af udfordringerne ved store data/domæne modeller er at de samme entiteter/tabeller
bliver brugt i mange forskellige sammenhænge (usecases/contexts).
Viden om hvilke associationer/kolonner/properties man må/kan bruge ligge gemt væk i koden og ender med at være implicit viden. Eksempler på dette er små huske regler folk bliver fortalt: “Du må ikke joine disse tabeller med mindre at kunden er i restance” eller “den property har kun en gyldig værdi hvis xxxx er sandt”.
Et andet problem er, at vi i normaliseringens og genbrugets navn foretrækker at genbrug de samme entiteter/tabeller til at repræsentere to (eller flere) entiteter i vores domæne der benytter samme navn uden at stille spørgsmålstegn til om det er det i virkeligheden er det samme koncept (eller syn) eller om der er tale om et andet koncept med sammenfaldende navn. Inden for et hvert domæne, f.eks. handel, findes der mange sub-domæner, der har deres egne behov og specialiteter. En af årsagerne til at vi får så store modeller er at vi ikke splitter vores modeller op mht. sub-domæner.

Sub-domæner inden for Handels (Retail) domænet
Blot fordi nogle usecases alle arbejder på en entitet kaldet “Produkt” behøver det ikke betyde at det er det samme koncept eller samme betydning (af “Produkt”) som usecasene tillægger entiteten. Desværre lærer de fleste at os kun at lede efter navneord (entiteter) og verber (funktioner) når vi skal analysere usecases/stories/etc. Der mangler en generel vejledning i at gennemskue om de navneord/entiteter vi finder virkelig omhandler det samme koncept eller det samme syn på et koncept. Det er risikabelt automatisk at ophøje fælles Entiteter til Sub-domæner/services. I rigtig mange organisationer er det desværre hvad der er oftest sker. Vi har en Kunde service eller en Produkt service. Det behøver i sig selv ikke være dårligt hvis definitionen af f.eks. Kunde er sammenhængende. Der hvor det bliver problematisk er når vi tager data/syn på en Kunde fra andre sub-domæner (f.eks. Fakturering, Shipping, etc.) og blander ind i Kunde sub-domænet, med det resultat at Kunde sub-domænet vokser i kompleksitet og stille og roligt får mindre og mindre data samhørighed (data cohesion), da den forsøger at være noget for alle eller alt for ingen (det er svært at tilfredsstille alles forventninger uden at skuffe dem eller selv bukke under for presset). I disse tilfælde bliver vores Service grænser slørede.
Når vi får øer af data/funktionalitet på denne måde opstår der behov for at vores service kalder andre services for at få den nødvendige information fra dem for at den kan udføre sin opgave. Hvordan kan opnå denne information uden at bruge en form for 2 vejs kommunikation (f.eks. synkrone WebService/REST kald over HTTP) mellem ens egen service og de andre services som man er afhængige af?
Data service øer, synkron komminikation og kobling
Konklusion: Hvis vores Service er velafgrænsede (dvs. at de data og den logik vi har behov er til stede i servicen) og har gennem vores implementation har opnået kommunikations mæssig samhørighed og lagdelt samhørighed har vi skabt fundamentet at tage skridtet videre og opnå Temporal samhørighed og dermed temporal afkobling mellem vores services. Desto højere samhørighed vi har, desto mindre afhænger vi af andre Services for at vores egen service kan klare sine opgaver. Med det samme services får behov for at snakke med hinanden begynder de at vide for meget om hinanden hvilket øger vores koblingen (både den temporale kobling og den datamæssige/funktionelle kobling hvilket mindsker den kommunikations mæssige samhørighed).
I en kommende blog post vil jeg gå i dybden med hvordan man kan analysere sit domæne og identifiere sub-domæner og services.
Andet SOA Princip: Services er autonome
Autonomi betyder at vores Services er selvstændige og i videst muligt omfang ikke direkte afhænger af andre services for at kunne fungere og udføre deres opgaver.
97% af de SOA løsninger jeg har set, benytter sig hovedsageligt af synkrone service kald som integrations form. I nogle sammenhænge er det umuligt at undgå synkrone integration, men i de fleste sammenhænge er det bestemt muligt at undgå dem, såfremt man sørger for at overholde Første SOA Princip “Grænser er eksplicitte” beskrevet ovenfor.
Hvorfor er synkron integration så problematisk?
Den temporale (tidsmæssig) og kontrakt mæssige kobling er åbenlys (vi afhænger af at de andre services er tilgængelige for at vores service kan fungere og vi er afhængig af at de ikke ændrer deres kontrakter på en måde der kræver at vi tvinges til at følge med). Men der er mange andre udfordringer som gør synkron integration endnu værre. Lad os tage udgangspunkt i nedenstående sekvens diagram og identificere nogle at de problemer der opstår når man integrerer med synkrone funktions kald (og det er uanset om vi snakker om WebServices eller REST):
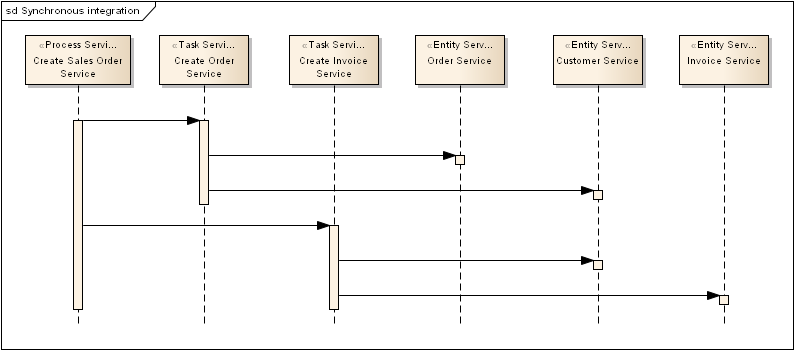
Synkron integrations scenarie
Her har vi en Process Service “Opret Salgs Ordre Service” (Create Sales Order Service) som i sekvens (kunne måske foregå parallelt) kalder to Task services “Opret Ordre Service” (Create Order Service) og “Opret Faktura Service” (Create Invoice Service). Disse task services kalder hver i sær to Entitets/data Services hhv. “Ordre Service”, “Kunde Service” og “Faktura Service”.
Problemer med ovenstående eksempel:
- Latens tiden fra “Opret Salgs Ordre Service” (Create Sales Order Service) bliver kaldt, til begge Task services har fået kaldt deres to Entitets Services og kan returnere
svaret.- Nogle gange kan man parallellisere nogle af disse kald og andre gang er der en tvungen sekvens pga. inter-service afhængigheder (f.eks. kan du ikke bruge kunden i den anden Task Service før kunden er oprettet af første Task service)
- Det er ikke unormalt at se eksempler på ovenstående hvor der er > 10 service kald for at udføre een process service.
- Hvis blot en af underliggende service er utilgængelig er HELE process servicen (og samtlige andre services der benytter samme underliggende service eller vores service) utilgængelig. Så hvis Faktura servicen er nede kan vi ikke modtage nye Ordre.
- De fleste processer, som den i vores eksempel, har trin der med fordel kan udføres på et senere tidspunkt. F.eks. er det for mange online handels systemer bedre at kunne modtage en Ordre, selv om Faktura servicen er nede. At fakturaen kommer minutter, timer til dage senere er sjældent et stort problem.
- Hvis et af service kaldene ovenfor tager lang tid, tager hele Process Servicen langtid.
- Hvis Service kaldene ovenfor opdaterer data og vi oplever Faults/Exceptions eller andre former for fejl (f.eks. IO fejl) står vi med et inkonsistent system med en kompleks kompensations logik til følge. Neden for har jeg givet et eksempel på hvilke udfordringer man løber ind i mht. kompensationer. Eksemplet er på ingen måde fyldestgørende. Den virkelige løsning er meget mere kompleks og skal kunne tage hensyn til at System B kan blive lukket ned/crasher i forbindelse med kompensations forløbet – også kendt som resume funktionalitet:
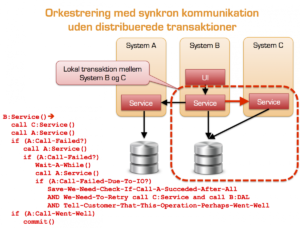
Transaktions kompensation ved synkron integration
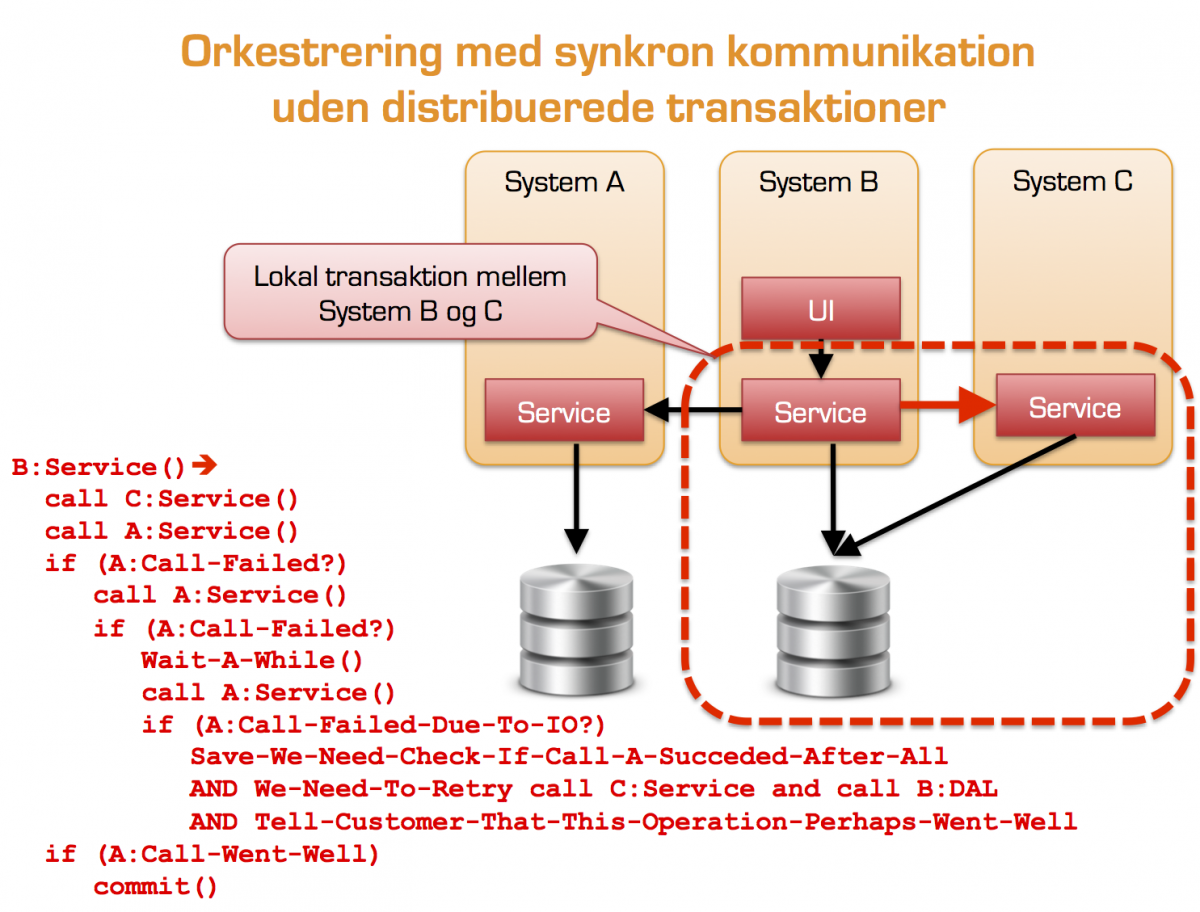
Grunden til synkrone og snakkesagelige services som ovenfor skyldes oftest brud på Første SOA Princip “Grænser er eksplicitte” som beskrevet ovenfor.
Konklusion: Når vores services har data/funktionalitets misundelse og har behov for at snakke med andre services begynder vores services at vide for meget om hinanden hvilket øger vores koblingen, latenstiden, stabiliteten, da vi afhænger af andre services tilgængelighed og kontrakt stabilitet. Alt dette mindsker vores autonomi og skaber effektivt et kort hus som nemt kan væltes. For at opnå en højere grad af Service autonomi, bliver vi nødt til at undgå integration via synkrone service kald (og nej det hjælper ikke at udføre kaldene med et async API, den temporale kobling mellem servicene er stadig den samme – vores service kan ikke fortsætte før den anden service har svaret). 2 vejs kommunikation i form af request/reply eller request/response kommunikation er ikke vejen frem, vi skal kigge i en anden retning for at finde en løsning på vores afkoblings og autonomi behov.
Dette bliver emnet for næste blog post. Indtil da er jeg rigtig interesseret i at høre jeres holdninger og ideer 🙂
[…] Danish version: https://qed.dk/jeppe-cramon/2014/02/01/soa-synkron-kommunikation-data-ejerskab-og-kobling/ […]
Virkelig spændende læsning, og jeg er specielt glad for vinklen med autonome services! Der er 117 umiddelbare spørgsmål, men starter med et par af dem: (1) Nogen idé om hvorvidt synkrone services faktisk er den del af performance-problemet i Proask? (2) Kan synkrone services ses som det umiddelbare resultat af menneskelig tankegang og den slags programmeringssprog og middleware som vi normalt bruger? (3) Hvordan underviser jeg monstro mine software engineering studerende så de ikke laver den samme slags fejl? (OK, den sidste skal jeg selvfølgelig selv finde ud af, men kan jo være du har en holdning..)
mvh Ulrik
Hej Ulrik
Ad 1) Jeg har ingen anelse om hvordan deres arkitektur er opbygget. Det er årstallet for initiering og problemerne med performance får mig til at gisne om at de nok også har anvendt synkron integration (eller måske simuleret synkron kommunikation gennem async 2 vejs kommunikation aka request/reply gennem Biztalk).
Ad 2) Jeg tror du er spot on. Det er meget nemmere at tænke sekventielt og implementere sekventielt. Desværre synes jeg det teoretiske fundament jeg og formentlig mange andre fik gennem universitetet er for tyndt mht. de problemer der opstår når man implementerer sekventielt i et distribueret setup. Jeg har rådgivet flere virksomheder der var SOA’ificerede. Når man gik de udviklere der implementere services (udstillede eller konsumerede) eller dem der stod for orkestrering var de generelt ret blanke når snakken gik på de basale integrations mønstre, idempotens, messaging patterns, etc.
Ad 3) Det jeg synes gav mig mest at tænke over var når nogen dragede analogier til hvordan vi ville gøre tingene uden computer. Både mht. hvordan man integrerede i gamle dage med dokumenter og beskeder, men også hvordan vi mennesker, som autonome aktører, interagerer. Jeg har tidligere holdt et foredrag hvor jeg dragede samme analogi tilbage til Matador og Mads Skjerns manufaktur forretning ved at gennemløbe et købs scenarie. Det plejer at give et meget godt grind blandt et teknisk kyndigt publikum. Jeg har også testet analogien i flere omgange på IKKE tekniske personer, som hurtigt kunne se og forstå det komiske i den måde vi integrerer. Foredraget er på engelsk og video og slides kan finde her: http://www.tigerteam.dk/2013/slides-and-video-from-our-iddd-tour-dk-talk-what-soa-do-you-have-with-extended-eda-and-cqrs-material/
Tak for din super elegante måde at kommunikere og diskutere kerneudfordringerne i et sagligt abstraktionsniveu så folk som mig med en mere forretningsbaseret tilgang til IT kan være med. Det er virkelig essensen af ægte Business IT Alignment og måske endda beyond alignment – systemisk tænkning – vi her er vidne til.
Jeg glæder mig meget til kommende afsnit…. Jeg føler mig overbevist om at dette bringer noget stor med sig.
Hej Steen. Mange tak 🙂
[…] I en traditionel løsning kunne man forestille sig at der ville være en CreateNewUser()-metode, som udfører de forskellige handlinger igennem kald til andre metoder / services (hvor services her er klasser i andre namespaces / projekter, eller på andre web services). Men dette ikke en tilgang uden problemer (læs “Hvorfor er synkron integration så problematisk?” her). […]
[…] låser ressourcer, mens de er aktive Services er autonome, så hvis en anden service, gennem Distribuerede transaktioner, får lov at låse resourcer i din […]
[…] Asynkron besked håndtering (som er helt på linie med min holdning) […]